Interpreting Facebook CAN: How to Give Artificial Intelligence the Power of Artistic Creation
(Original title: Reading Facebook CAN: How to Give Artificial Intelligence the Power of Artistic Creation)
The GAN (Generic Antagonism Network), which can iteratively evolve and imitate specified data features, has been recognized as a good way to deal with image generation problems. Since its introduction, there have been many related research results in image enhancement, super-resolution, and style conversion tasks. The effect is amazing.燑/p>

Using GAN to achieve image super-resolution and style conversion examples
This year, there is also the use of GAN's simple strokes to the image conversion model pix2pix. In addition to converting the cats in the following diagrams, there are buildings, shoes, and bags. The model is very imaginative, and it doesn't matter if you just paint it. Interested readers can draw to the demo address themselves.
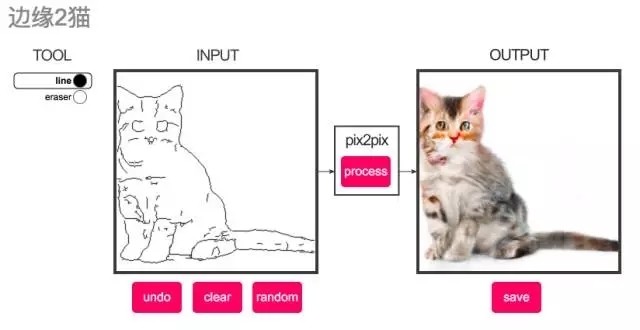
Example of converting lines to cats in demo
Can GAN generate works of art?
Since GAN already has such image generation capabilities, we can't use GAN to generate works of art. After all, many modern works of art do not seem to be very complicated to see photos, such as the following one; not to mention hyperrealism.
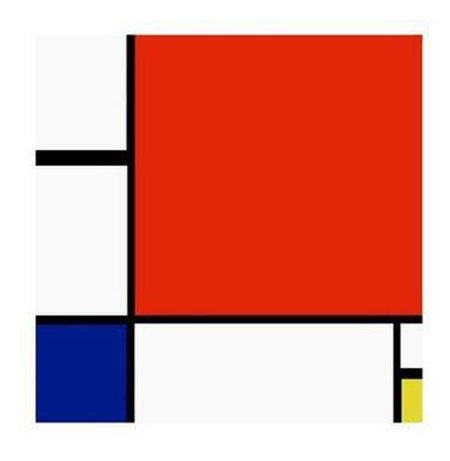
Mondrian "The Composition of Red, Yellow and Blue"
However, it is not so simple to create a work that humans find artistically valuable. Humans like innovative works. Humans do not like works that are completely imitated; “Monalisa†and “Lanting Collection Preface†are recognized as the world's art treasures only by the original author’s original edition. Even if people of later generations create works based on them, they must Having its own innovation can bring new artistic value before it can be recognized by viewers.
According to the basic structure of the GAN, the discriminator D needs to determine whether the image generated by the generator G is the same category (feature) as the other images that have been provided to the discriminator D. This determines the best image output. It can only be the imitation of existing works. If there is innovation, it will be recognized by the discriminator D and it will not achieve the goal. The above examples of GAN can reflect this feature brought about by discriminator D. Art works generated by GAN are also destined to lack substantive innovation and have limited artistic value.
So, can we make GAN have some innovative capabilities that allow these innovations to have artistic value, and the works with these innovations can also be recognized by humans? The three-part collaboration between the Rutgers Arts and Artificial Intelligence Laboratory, the Facebook Artificial Intelligence Institute (FAIR), and the Art History Department of the Charleston College provided an answer through the CAN (Creative Adversarial Network). . François Chollet, the author of the neural network library Keras, also recommended this article on Twitter.

First look at how the work

Some artwork produced by the CAN model
It can be seen that the style of the generated artwork is very diverse, ranging from simple abstract paintings to complex combinations of lines, as well as different levels of content. There are also comparative test results in the paper. The works generated by CAN are not only more likable than those generated by GAN, and even human art works from Basel Art Exhibition are not comparable to CAN. (Specific data see later)
How to recognize artistic innovation
Just now, art works need to be innovative. C in CAN is Creative and innovative. How to measure innovation and how to achieve it?
In the past, based on GAN image generation methods, humans can compare the trained network-generated images with objective facts (super-resolution, image-completion problems) or empirically judged (style-conversion issues) to measure The effect of the network; there have also been some earlier algorithms that allow humans to be part of the training feedback and guide the network's training process. But for this topic, we need to design an innovative system that can automatically train and generate, and measure the work. The previous method will not help.
At the same time, in the eyes of the authors, in order to be able to imitate the process of human art creation, an important part of the algorithm is to link the creative process of the algorithm with the previous works of art by human artists and, like humans, understand and understand the previous art. The ability to create new art forms is integrated. In order to be able to find a way to find an innovative indicator that can measure innovation and participate in iterative training, the authors have come up with a set of artistic theories.
According to DEBerlyne, from the perspective of physiological psychology, there is an indicator called “wake level†in the state of human beings. It can measure how alert and excited a person is; the level of arousal can range from the lowest sleep to rest to rage. ,excitement. While a work has the overall traits of “wake up potentialâ€, it can enhance or reduce the arousal level of the viewer; it is a comprehensive manifestation of the novelty, unexpectedness, complexity, polysemy, and doubtfulness of the works. The higher the attribute, the higher the awakening potential of the work.
Colin Martindale (1943-2008) proposed a hypothesis that at any moment, creative artists will try to increase the "wake up potential" of their work, which is a way to broaden the boundaries of the creative habits. However, such an increase must make the observer's negative reactions as small as possible (as far as possible, so that observers do not put extra effort), or else too aggressive products will be negatively evaluated.
Colin Martindale also put forward a hypothesis that he believes that when the artist explores more of the role of the artistic style, the conversion of the artistic style will have the effect of improving the “awakening potentialâ€.
This set of theories is just a few of the theories that explain the artistic innovation, but they together give two computational indicators that can be used for iterative training:
The degree of innovation in innovative works should not be too high, and the viewers should not think that the work is an art work as possible as possible;
The new artistic style is the embodiment of innovation.
CAN network constructionBased on these two indicators extracted, the prototype based on GAN constructed such a new adversarial network CAN.
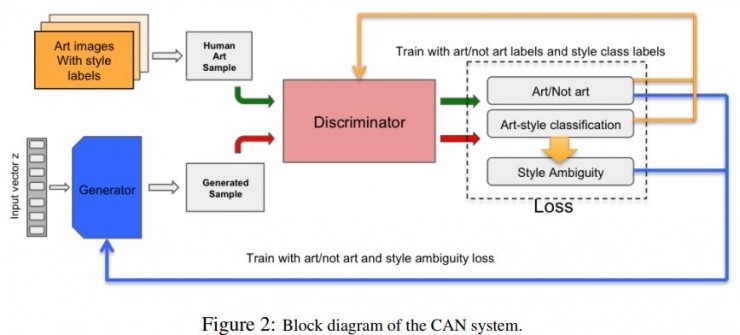
System Block Diagram of CAN Model
First of all, with regard to “Indicator 1: The degree of innovation in innovative works cannot be too high, the viewer does not consider the work to be a work of art as possible as possibleâ€, it can be converted into a classic confrontational network, G generates images, passes through the works of art. The trained D judges whether the G-generated image is a work of art. The image generated by such an adversary network can already be regarded as a work of art.
Then, the model in the paper also adds a new structure to deal with artistic style according to "Indicator 2: New artistic style is the embodiment of innovation."
The paper used 25 different labelled works of art for the training of D, including more than 75,000 pieces of the style of abstract impressionism, cubism, modernism, baroque, and Early Renaissance. The trained D, in addition to returning an image "is it a work of art," has feedback on "whether it can tell what kind of artistic style the image is." G then uses D's feedback to generate images that are as difficult as possible to distinguish between the artistic styles - those that are difficult to categorize into existing categories are innovations.
Whether it is an artistic work or whether it is difficult to distinguish the artistic style is a signal of two opposites. The former signal will force the generator G to generate an image that can be regarded as an art, but if it is in the existing artistic style category In the middle of this goal, the discriminator D can discern the artistic style of the image, and then the generator will be punished. In this way, the latter kind of signal will cause the generator to generate works that are difficult to distinguish between styles. Therefore, the two signals can work together to allow the generator to explore the boundaries of the artwork in the entire creative space as much as possible, while maximizing the generated works as much as possible outside the existing standard art style.
This is the meaning of the paper titled "CAN: Creative Adversarial Networks Generating "Art" by Learning About Styles and Deviating from Style Norms". The creative confrontation network can learn the art style and then deviate from these existing styles to create art.
Also said artistic style, is now "not good to distinguish", "good resolution" not?
Compared with GAN, CAN's increased feedback is "is it difficult to distinguish the artistic style", and the pursuit of the style of the generated image art is difficult to distinguish. Although according to the derivation of the art theory, the new artistic style is an innovation, since it is adding more feedback, is it possible to pursue the “distinguishable image art style� Will it also produce good works?
From another point of view, if the pursuit of "unresolvable" CAN is indeed better than the pursuit of "easy to distinguish" CAN-generated images, then this is the best embodiment of the model's selection of reasonable feedback.
Do it. In addition to CAN, three models were created for comparison.
DCGAN ? 4x64: DCGAN (deep convolutional generation countermeasure network) trained in art, with an output resolution of 64x64
DCGAN 256x256: Compared to DCGAN 4x64, the generator adds two layers of network with an output resolution of 256x256
scCAN:style-classification-CAN, the pursuit of "generated image art style easily distinguishable" CAN
The screens generated by these three models are as follows
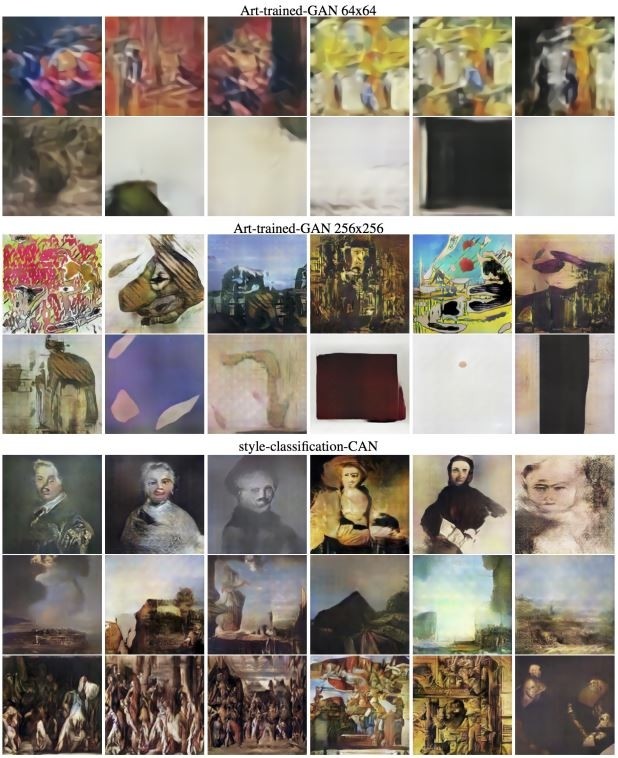
Two DCGAN and scCAN generated screens
The scCAN generated screens do have recognizable styles such as character close-ups, scenery, or group images. But intuitively it doesn't seem like much to please.
Let's look at a group of images generated by CAN. The top is the highest human evaluation, and the bottom is the lowest human evaluation. It should be said that it is much better than the image generated by scCAN.

Can humans evaluate the highest and lowest CAN-generated images Humans can give a bit of CAN imagery?
According to the previous image, it can be seen that the effect of CAN is certainly good. The DCGAN 256x256 image is actually quite good. Can the image of CAN be really difficult to distinguish the creator from the people who are viewing it? How does it compare with the works created by real artists?
For specific comparisons, several experiments were done in the paper to allow humans to rate different groups of works.
Experiments 1:2: Plowing Vinegar, Olives, Shades, Accounts, Industry, Business (13) Images of the images generated by the GUANYUAN leg ditch, the images generated by DCGAN, and a total of 4 sets of works by ordinary people. Determine whether these works come from people or computers, and rate the work.
Results: 53% of people in experiment 1 thought that the image of CAN was from humans. The image of DCGAN 64x64 was from 35% of people; in experiment 2, the ratio of CAN image from human being was 75%, DCGAN 256x256 was 65%. The works of the artists from the Abstract Impressionists are undoubtedly the highest proportion, but it is interesting that in the two experiments, the percentage of works from the Art Basel exhibition is not as high as that of CAN (41% in experiment 1 and 48% in experiment 2). .

The experimental data of Experiment 2 first allowed human evaluators to evaluate the work from several angles and then judge whether it was created by humans. Percentage of evaluators who consider the image to be human creation is Q6
Experiment 3: Let human evaluators rate the work from the perspective of intention, visual structure, interactivity, and inspiration. The result is that CAN has the highest score. This result is unexpected.
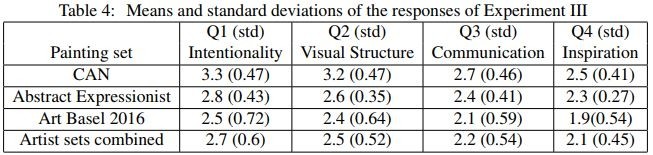
Experiment 3 result data
Experiment 4: In order to confirm the novelty and aesthetic performance between CAN and scCAN, a group of art history students were asked to evaluate randomly selected CAN and scCAN images. The proportion of CAN images that are more novel is 59.47%, and the proportion of CAN images that are more aesthetically pleasing is 60%. There are indeed significant differences.
in conclusion
The paper stated that although such a model still does not have any semantic understanding of the concept of artistic style, it does demonstrate the ability to learn from previous works of art. As for why humans will give high scores to CAN in various aspects, the authors also hope to openly discuss with you.
 燑br>
燑br>
Wuxi Lerin New Energy Technology Co.,Ltd. , https://www.lerin-tech.com